

안녕하세요~
카카오엔터테인먼트에서 백엔드 플랫폼을 개발하고 있는 Jace입니다.
작금의 시대에 소프트웨어는 산업 전반적으로 다양한 영역에서 다양한 요구사항에 의해서 만들어지고 사용되고 있으며 당연하게도 이런 소프트웨어는 요구사항대로 잘 작동하는지 다양한 방식으로 검증하게 됩니다. 이런 검증 방식 중엔 개발자가 직접 작성하고 관리하는 Test Code가 포함되어 있으며 Test Code의 중요성은 별도로 설명하지 않아도 우리는(개발자) 이미 잘 알고 있습니다.
제가 지금껏 만나본 그 어떤 개발자도 Test Code가 중요하지 않다고 말하는 개발자를 본 적이 없습니다.
이처럼 대다수의 개발자들은 Test Code의 중요성과 필요성에 대해서 인지는 하고 있긴 하지만 아이러니하게도 많은 수의 개발자들이 이런저런 핑계로 Test Code 작성을 안 하거나 작성된 Test Code 관리를 소홀히 하는 걸 많이 보게 됩니다.
애써 작성한 Test Code가 의미가 없는 Test Code라면?
애써 작성한 Test Code가 관리되지 않아 문제의 대상이 되어버린다면?
결국엔 Test Code 작성은 불필요한 절차가 되어버리고 외면받는 대상이 되어버릴 것입니다.
개발자라면 누구나 다 중요하다고 생각하는 Test Code가 찬밥 신세를 당하지 않고 우리가 구현/운영하는 애플리케이션에 도움이 될 수 있는지에 대해 Test Code가 Why(왜?) 필요한지 알아보고 더 나아가 What(무엇을?) 테스트해야 하고 How(어떻게?) 테스트해야 하는지 알아보도록 하겠습니다.
Why?
미국의 소프트웨어 공학자 프레드릭 브룩스는 본인의 저서 맨먼스 미신에서 소프트웨어는 계속해서 살아 움직이는 유기체와 같다고 말했습니다. 즉, 누군가의 의해 만들어져 사용되는 소프트웨어(이하 애플리케이션)는 어떠한 이유에서든 필연적으로 변경되게 되고 이런 변경으로 인해 정상적으로 작동하고 하고 있던 애플리케이션이 오작동할 가능성이 증가하게 됩니다.
또한 애플리케이션의 특정 기능 변경이 해당 기능 외의 다른 기능에 문제를 유발하는 부수효과(Side effects)를 가져 올 수도 있으며, 이런 부수효과로 인해 변경 이전 정상적으로 작동하던 기능이 작동하지 않는 회귀 오류(Software regression)를 발생시키게 되며, 회귀 오류는 애플리케이션이 Release 된 후 시간이 흐르거나 기능이 많아질수록 발생할 확률 또한 선형적으로 증가하게 됩니다.

이렇게 발생하는 회귀 오류를 검증하기 위해 다양한 방식의 테스트가 이루어지게 되는데요. 대표적인 테스트 방법으론 UI, Service, Unit Test가 있으며 각 테스트 방법의 복잡성과 속도는 다음 그림과 같이 피라미드 형태를 띠며 이를 TestPyramid라 부릅니다.
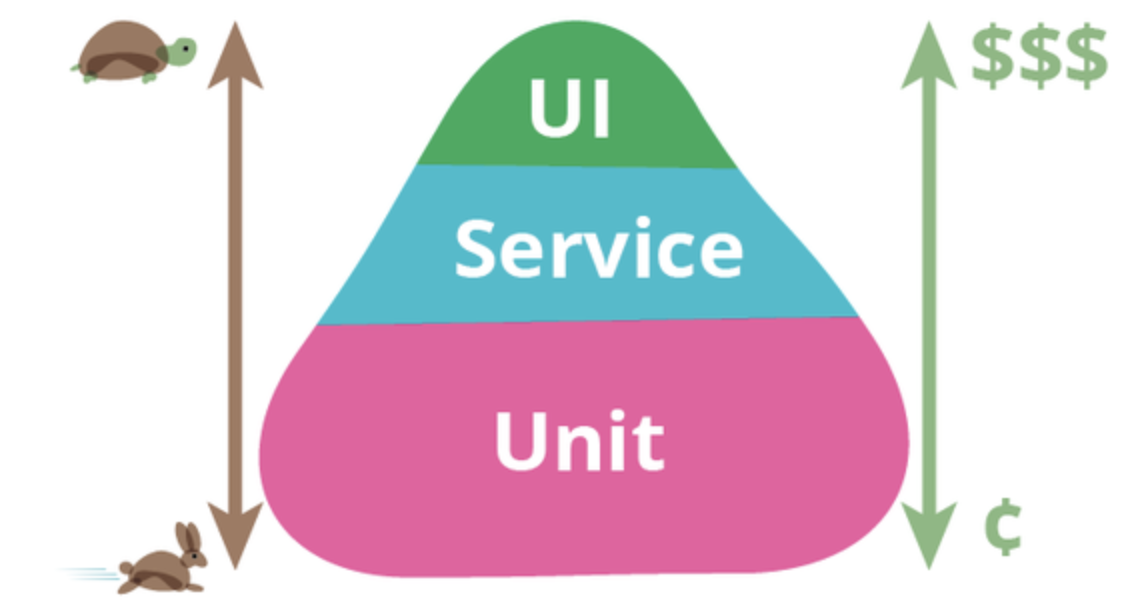
테스트 피라미드에서 위로 갈수록 테스트 수행 속도는 느리고 복잡하며 아래로 갈수록 반대가 됩니다.
각 테스트 방법은 테스트라는 궁극의 목표는 같지만 각기 다음과 같은 목적과 특징을 가지고 있는 점이 다릅니다.
- 테스트 수행 속도가 빠르다
- 테스트 작성/관리 비용이 낮다
- 기능이 정상적으로 동작하는(기대 결과, 에러 등등)지 여부에 대한 즉각적인 Feedback이 가능

Level 2 - Service Test (Integration Test)
- UI를 제외한 애플리케이션의 code base들의 외부 구성요소(Database, 외부 API 등)와 상호작용을 테스트
- UI Test와 비슷하게 종단 간 테스트를 진행하지만 UI 테스트를 다루는 복잡성을 피할 수 있음
- 보통 UI에서 호출하는 Endpoint(API)를 통해 테스트
Level 3 - UI Test(End to End Test)
- 실제 사용자가 이용하는 UI 기반으로 테스트를 진행
- 테스트 수행 속도가 느림
- 자동화된 테스트를 위한 테스트 작성 비용이 높음
▫️ Selenium, Sahi 등 테스팅 Tool을 사용하여 작성하고 테스트함 - 테스트가 깨지기 쉬움
다른 테스트들도 중요하지만 애플리케이션 개발자가 기능 구현 시, 해당 기능의 테스트를 위해 가장 많이 반복하는 테스트는 Unit Test이고, 그만큼 다른 테스트에 비해 상대적으로 중요한 Unit Test 구현 시에 무엇을 테스트해야 하고 어떻게 테스트해야 하는지에 대해서 좀 더 알아보도록 하겠습니다.
What?
테스트 코드 구현(Aka Unit Test)에 익숙지 않은 다수의 개발자분들이 입을 모아 하는 말이 있습니다.
"무엇을 테스트해야 하는지 잘 모르겠다"
그렇습니다. 테스트 코드를 작성하고 싶긴 한데 무엇을 테스트해야 하는지 막연하기만 합니다.
이런 막연함 속에서 테스트 코드를 작성하게 되면 어떻게 될까요?
몇 가지 예제를 통해서 확인해 보도록 하겠습니다.
예제 1) 다음 Test Code의 가장 큰 문제점은 무엇일까요?
@Test
public void test() {
logService.addLogForUserHistory("testAdminId", 0L, "testId");
}✔️ 검증이 없음으로 무엇을 테스트하는지 알 수 없음
예제 2) 다음 Test Code의 가장 큰 문제점은 무엇일까요?
@Test
public void profileByIds() {
List<UserInfo> result = client.profileByIds(Lists.newArrayList(TEST_ID));
assertThat(result).isNotNull();
}✔️ 검증이 존재하긴 하지만 NotNull 체크만으론 명확한 테스트 의도를 알 수 없음
예제 3) 다음 Test Code의 가장 큰 문제점은 무엇일까요?
@Test
void testFindByKeys() {
assertThat(savedData).isNotEmpty();
var result = repository.findAllByKeysOrderByIdDesc(...);
log.info("result {}",result);
assertThat(result).isNotEmpty();
}✔️ 테스트를 위해 사전에 준비된 데이트를 검증
✔️ 검증 또한 테스트를 위해 임의로 저장한 데이터를 조회 후 empty 여부만을 검증하고 있어 실제 의도와 달리 데이터만 존재하면 테스트가 성공함
위의 테스트 예제는 실제 Release 된 애플리케이션에 대한 Unit Test Code입니다.
(제가 공개 가능 수준으로 코드를 변경하였지만 실제 테스트 구현 로직은 그대로입니다.)

저 또한 테스트 코드를 처음 접하던 시기에 이런 식의 테스트 코드를 작성했었던 기억이 있으며, 상당수의 개발 조직에서 지금 이 시간에도 이런 의미 없는 테스트가 만들어지고 있거나 이미 가지고 있다고 감히 단언드릴 수 있습니다.
그렇다면, 이런 의미 없는 테스트 코드가 만들어지는 이유가 뭘까요?
다양한 이유가 존재하겠지만 제 생각에 가장 큰 이유는
"무엇을 테스트해야 하는지 잘 모르겠다"
에서 기인한 거라 생각합니다.
그렇다면 과연 우리는 무엇을 테스트해야 할까요? 다 같이 큰 소리로 읽어 보겠습니다!
"Application Design(명세)를 테스트하라!"
그렇습니다. 우리가 구현하는 애플리케이션의 디자인(명세)을 테스트해야 합니다.
이게 무슨 말인지 좀 더 구체적으로 살펴보도록 하겠습니다.
우리가 구현하는 대부분의 애플리케이션의 내부에는 다음 그림과 같이 많은 객체들이 다른 객체들과 상호 협력하며 작업을 처리하게 됩니다. (객체지향 프로그래밍(OOP) 스타일의 Program language에 한함)
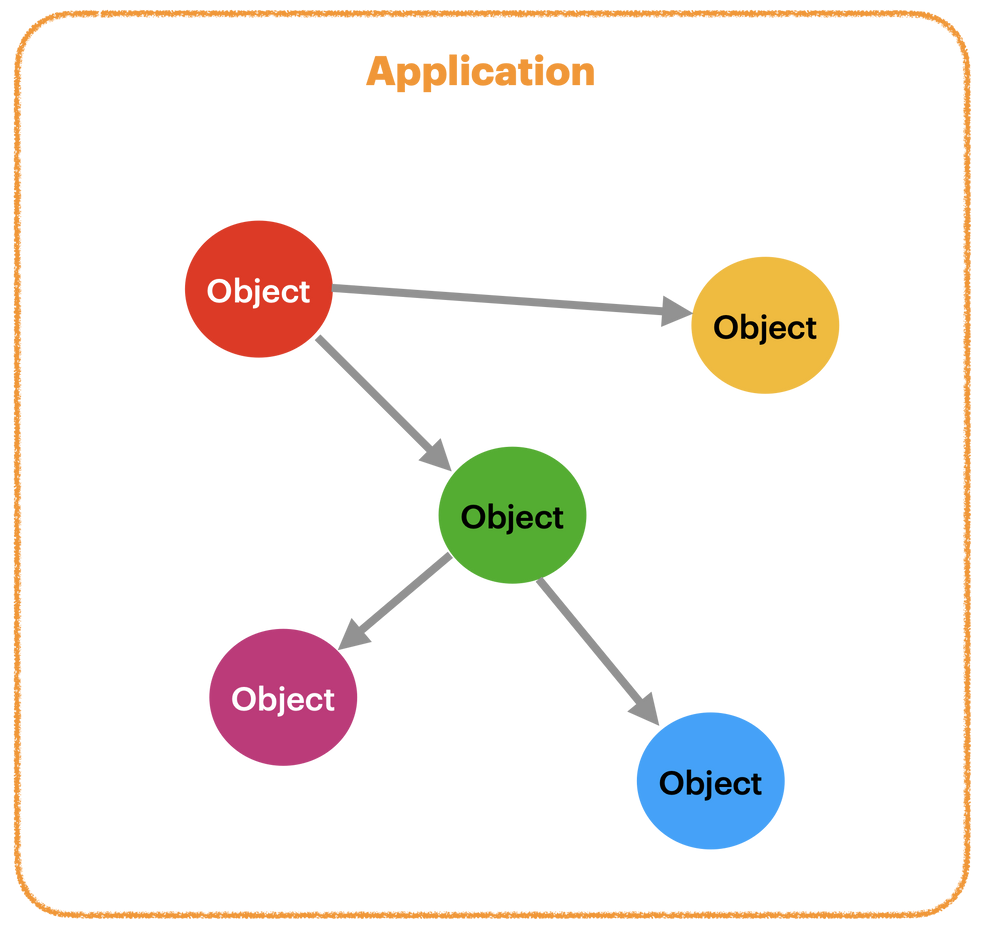
여러 객체 간 협력에 필요한 것은 “어떻게” 가 아닌 “무엇"(명세)이며 이 무엇을 우리는 '인터페이스'라 부르며 다음과 같이 요약해 볼 수 있습니다.
인터페이스
- 클라이언트 코드에게 반드시 필요한 명세
▫️ 클라이언트 코드 입장에서 협력대상 객체(코드)는 '어떻게 처리되는지' 보단 '무엇을 처리하는가'가 중요 - 협력하는 객체 사이의 계약
- 추상화의 결과
상호 작용하는 객체(코드) 간 협력은 바로 이 인터페이스 기반으로 이루어지게 되며 인터페이스를 통해서 객체는 협력 대상 객체가 요청을 어떻게 처리하는지 알 필요 없이 정해진 명세 기반으로 호출하고 응답에 대해 처리하면 그만이게 됩니다. 이를 OOP에선 정보은닉(Information Hiding)이라 부르며, 중요 원칙 중 하나라는 것은 여러분들도 너무 잘 알고 계실 것입니다.
왜 무엇을 테스트해야 하는지 설명하는데 갑자기 정보은닉이 튀어나왔는지 의아해하시는 분들도 계실 텐데요. 이유는 우리가 작성하는 테스트 코드 또한 Production code를 사용하는 여러 클라이언트 코드 중 하나일 뿐이고 그렇기에 이 원칙(Information Hiding)은 테스트 코드에게도 당연히 적용되어야지만, 우리가 구현하는 객체들은 자율성을 보장받을 수 있고 그렇기 때문에 테스트 대상(System Under Test - 이하 SUT) 입장에서 테스트 코드 또한 정보은닉 대상이 되게 됩니다.
이 전제 조건을 바탕으로 앞서 언급했던
"Application Design(명세)를 테스트하라!"
명제를 곱씹어 보면 테스트 코드는 SUT가 제공하는 명세의 경우의 수(case)로 정의할 수 있습니다.
예를 들어 보겠습니다.
public void removeGroup(SettlementGroupMember group) {
AssertUtils.notNull(group, "group must not be null");
this.groups.remove(group);
}
위 메서드를 호출하는 Client 코드에서 겪을 수 있는 경우의 수는 어떻게 될까요?
- "SettlementGroupMember"이 null인 경우 에러가 발생한다.
(AssertUtils.notNull은 검증 대상이 null 경우 IllegalArgumentException이 발생함) - "SettlementGroupMember"가 null 아닌 경우 객체의 group목록에서 해당 group이 삭제된다.
이 메서드를 호출하는 클라이언트 코드 입장에서 겪을 수 있는 경우의 수는 위와 같이 두 개입니다.
Why? "removeGroup" 메서드가 그렇게 디자인되어 있기 때문입니다.
[참고] 위 코드에는 나타나 있지 않지만 인스턴스가 생성되었다면 this.groups은 null일 수 없습니다.
즉, SUT의 구현된 디자인(명세)을 기반으로 경우의 수를 정의하게 되면 이 경우의 수가 Test Case 되게 되고, 우리는 이 Case에 대한 테스트 코드를 구현해 주면 됩니다.
@Test
@DisplayName("파트너 회원에 정산그룹 추가시 전달된 정산그룹이 null 이면 에러가 발생한다")
void sutAddGroupArgsNullError() {
var sut = PartnerFixture.createPartner("memberId", "Password!@3");
Throwable thrown = catchThrowable(() -> sut.addGroup(null));
assertThat(thrown)
.isInstanceOf(IllegalArgumentException.class)
.hasMessage("group must not be null");
}
@Test
@DisplayName("파트너 회원의 정산그룹 삭제가 정상적으로 처리되면 정산그룹 목록에서 해당 그룹이 삭제 된다")
void sutRemoveGroupArgsNullError() {
var sut = PartnerFixture.createPartner("memberId", "Password!@3");
var removalGroup = createSettlementGroupMember("removalGroupId");
sut.addGroup(removeGroup);
sut.addGroup(createSettlementGroupMember("normalGroupId"));
sut.removeGroup(removeGroup);
assertThat(sut.getGroups()).hasSize(1);
sut.getGroups().forEach(group -> {
assertThat(group.getId()).isNotEqualTo("removalGroupId");
});
}
[참고] 일반적으로 테스트는 SUT의 상태 또는 행위를 검증하게 됩니다. 이 중 행위 검증의 경우 테스트 코드가 SUT의 상세 구현을 알아야지만 가능하게 됩니다. 하여 가급적 Mock을 사용한 행위 검증의 경우 지양하는 것이 좋으나, 테스트 코드를 통해서 구현을 강제하는 목적으로 행위 검증을 하는 경우도 존재합니다.
예제) 객체 영속화 시에 특정 Repository interface를 구현한 경우만 허용하고 싶은 경우, 테스트 코드에서 해당 interface의 특정 메서드가 호출되었는지를 mock을 통해서 특정 행위의 실행 여부를 검증하게 되면 차후 코드 변경 시 이 행위 검증을 통해서 의도한 구현이 유지되는지를 확인할 수 있습니다.
How?
무엇을 테스트해야 하는지 알아봤으니 이제 어떻게 테스트 코드를 구현하는지에 대해서 살펴보도록 하겠습니다.
여기서 어떻게? 란 특정 테스트 기법과 tool에 대한 이야기가 아닌 어떻게 하면 테스트하기 쉬운, 즉 Testable 한 (테스트 용이성) Production코드를 구현하는지에 대해 다뤄 보도록 하겠습니다.
테스트하기 쉬운 코드
다음과 같은 특징을 가지고 있는 경우 테스트 하기 용이한 코드가 됩니다.
- Deterministic Code(결정적 코드)
결정적 코드란 같은 입력에 항상 같은 결과를 반환하는 코드를 말합니다.// sut public int plus(int x, int y) { int result = x + y; return result; } @Test @DisplayName("10 더하기 20 은 30 이다") void sutPlus10And20Then30() { var sut = new Testable(); var actual = sut.plus(10, 20); assertThat(actual).isEqualTo(30); } - 외부 상태를 변경하지 않는 코드 - No side effects
부수효과가 없는 코드는 테스트하기 쉽습니다 위 예제는 결정적임과 동시에 부수효과가 없는 코드입니다
테스트하기 어려운 코드
반면 테스트하기 어려운 코드는 다음과 같은 특징을 가지고 있습니다.
- Non-deterministic Code(비 결정적)
결정적인 코드와 반대로 실행 시점마다 결과가 달라지는 코드를 말합니다.public String getTimeOfDay() { LocalDateTime now = LocalDateTime.now(); if (now.getHour() >= 0 && now.getHour() < 6) { return "Night"; } if (now.getHour() >= 6 && now.getHour() < 12) { return "Morning"; } if (now.getHour() >= 12 && now.getHour() < 18) { return "Afternoon"; } return "Evening"; }
위 코드에서 "LocalDateTime now = LocalDateTime.now();"부분은 실행 시마다 달라지기 때문에 비결정적이며, 이는 테스트하기 어렵습니다. - 외부 상태를 변경하는 코드
public int plus(int x, int y) { int result = x + y; System.out.println(result); return result; }
위 코드 중 "System.out.println(result);"는 System console에 연산 결과를 출력하는 매우 간단한 코드지만 이는 외부 상태를 변경하는 부수효과를 가지고 있기 때문에 테스트하기 어렵습니다.
즉, 테스트가 용이한 코드를 작성(구현) 하기 위해선
1️⃣ 결정적 코드
2️⃣ 부수효과가 없음
위 두 가지 조건을 준수하면 됩니다. (물론 이 두 가지 조건을 준수하는 것이 쉽지는 않습니다..🥲)
자, 그럼 테스트가 어려운(비결정적 코드, 부수효과가 있는) 코드를 어떻게 하면 방지할 수 있을까요?
다음 코드는 이메일로 이벤트에 참여 가능한지를 확인하는 메서드입니다.
public void checkPossibleAttend(String eventId, String email) {
Assert.hasLength(eventId, "Event Id must not be empty");
Assert.hasLength(eventId, "Email must not be empty");
// 이메일 형식 확인
if (!EMAIL_REGEX.matcher(email).matches()) {
throw new IllegalArgumentException("Invalid email : %s".formatted(email));
}
// 비결정적 코드
var attendedCount = repository.count();
// 참여 가능 인원수 확인
if (attendedCount >= ATTEND_LIMIT) {
throw new EventLimitExceededException("Event Id : %s attend limit exceeded".formatted(eventId));
}
}
이 코드는 테스트하기 쉬울까요? 어려울까요?
"// 비결정적 코드"부분은 매번 수행 시마다 값이 다르기 때문에 테스트하기 어려운 코드입니다. 반면에 "이메일 형식 확인"과 "참여 가능 인원수 확인"은 결정적 코드로 테스트하기 쉬운 코드입니다.
이처럼 테스트하기 쉬운 코드와 어려운 코드가 섞여 있는 경우 해당 메서드는 테스트하기 어려운 메서드가 되어버리니 가능한 많은 수의 테스트하기 쉬운 코드를 얻기 위해선 이 둘을 분리해야만 합니다.
public void checkPossibleAttend(String eventId, String email, long attendCount) {
Assert.hasLength(eventId, "Event Id must not be empty");
Assert.hasLength(eventId, "Email must not be empty");
if (!EMAIL_REGEX.matcher(email).matches()) {
throw new IllegalArgumentException("Invalid email : %s".formatted(email));
}
if (attendCount < ATTEND_LIMIT) {
throw new EventLimitExceededException("Event Id : %s attend limit exceeded".formatted(eventId));
}
}
public long getAttendCount(String eventId) {
var attendCount = repository.countById(eventId);
return attendCount;
}
테스트가 어려운 부분과 쉬운 부분을 분리했습니다. 분리는 했지만 이 두 개의 메서드는 모두 실행되어야 하기 때문에 어디선가 두 메서드가 호출되어야 합니다. 과연 저 두 개의 메서드는 어디서 호출(만나야) 되어야 할까요?
메서드 호출이 A → B → C 순으로 호출되는 경우, C 메서드가 비결정적 또는 부수효과가 발생하는 메서드여서 테스트하기 어려운 코드라면 다음 그림과 같이 이를 호출하는 B, A 또한 C의 테스트 어려움이 전파되어 테스트하기 어려운 메서드가 되어버립니다.
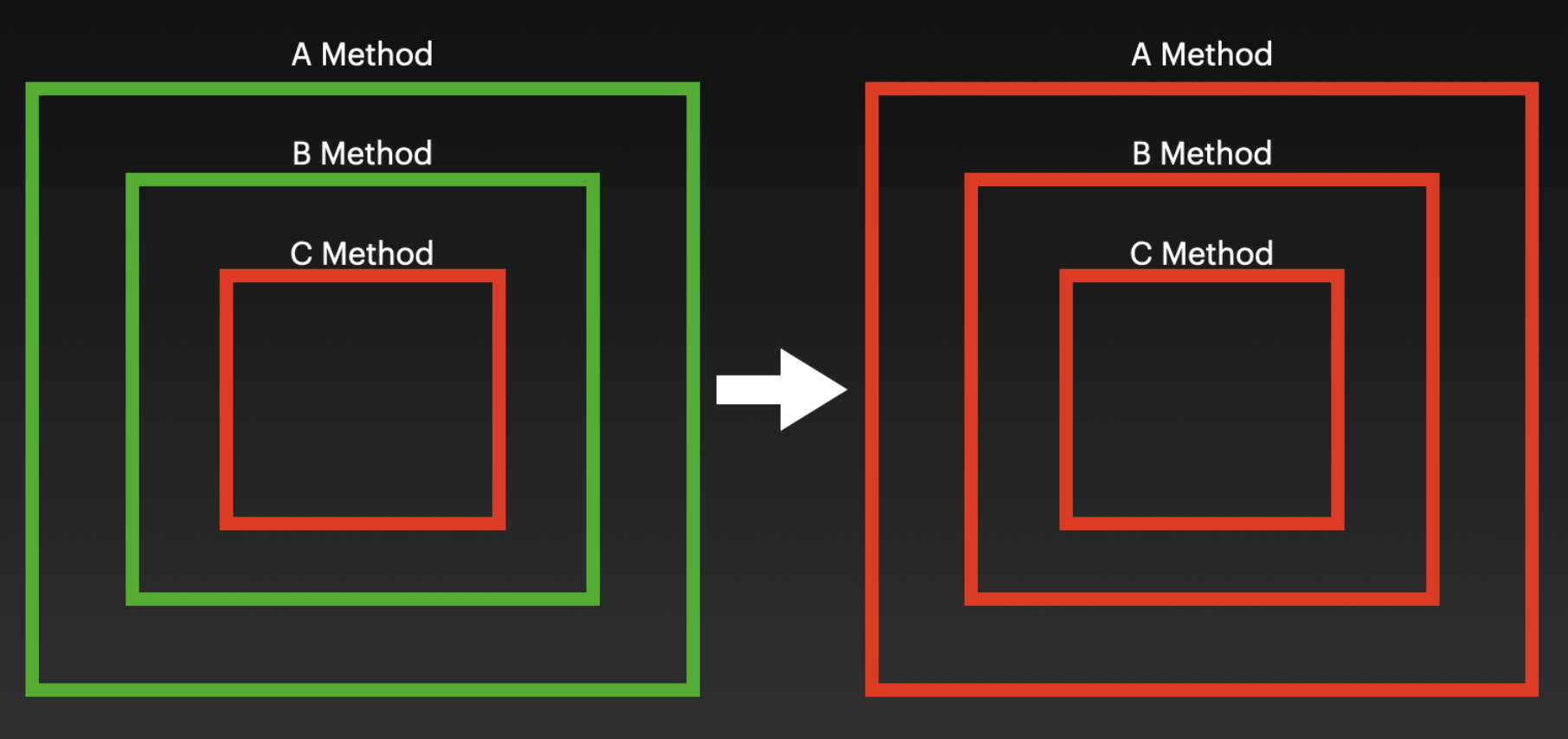
테스트가 쉬운 메서드와 어려운 메서드는 다음 그림과 같이 가장 바깥쪽에서 만나게 하는 것이 가능한 많은 수의 테스트가 용이한 코드를 얻을 수 있는 방법입니다.

그럼 예약 확인 메서드를 위 그림처럼 가장 바깥쪽에서 만나도록 변경해 보도록 하겠습니다.
public String attend(String eventId, AttendRequest request) {
Assert.hasLength(eventId, "Event Id must not be empty");
Assert.notNull(eventId, "AttendRequest Id must not be null");
long attendCount = getAttendCount(eventId);
domainService.checkPossibleAttend(eventId, request.getEmail(), attendCount);
var saved = eventRepository.save(request.toEntity(UUID.randomUUID().toString()));
return saved.getId();
}
public void checkPossibleAttend(String eventId, String email, long attendCount) {
Assert.hasLength(eventId, "Event Id must not be empty");
Assert.hasLength(eventId, "Email must not be empty");
if (!EMAIL_REGEX.matcher(email).matches()) {
throw new IllegalArgumentException("Invalid email : %s".formatted(email));
}
if (attendCount < ATTEND_LIMIT) {
throw new EventLimitExceededException("Event Id : %s attend limit exceeded".formatted(eventId));
}
}
public long getAttendCount(String eventId) {
var attendCount = repository.countById(eventId);
return attendCount;
}
이렇게 테스트가 쉬운 부분과 어려운 부분을 분리하고 어려운 부분에는 테스트가 필요하지 않을 정도로 얇게 유지하는 것을 Humble Object Pattern이라고 하고, 이런 식의 분리는 가능한 많은 수의 테스트가 용이한 코드를 확보하는데 많은 도움이 됩니다.
(애플리케이션 구현 시 특정 디자인 패턴 적용이 목적이 되어선 안된다는 점은 유의해야 합니다.)
[참고] 테스트가 어려운 메서드를 가장 바깥쪽으로 이동시키다 보면 가장 바깥쪽의 경계가 과연 어디인지 모호할 수 있습니다. 무조건 특정 Logic이 실행되는 최초 호출되는 경계까지 가는 경우 자칫 응집력이 떨어질 수 있으므로 개인적으로 해당 경계는 응집력이 떨어지지 않는 수준의 경계가 적합하지 않나 생각됩니다
좋은 테스트 코드 구현을 위한 Guide
좋은 테스트 코드를 구현하기 위한 최소한의 Guide를 살펴보겠습니다.
- 테스트는 SUT의 디자인(명세)을 기반으로 case를 정의
- 테스트명은 테스트 목적을 명확 들어낼 수 있게 작성
▫️ 본인만 이해할 수 있는 단어 또는 문장 사용은 지양하고 도메인 용어 기반에 명료하게 작성 - 테스트 케이스는 단일 검증 목적만 수행해야 함
- 가독성 높고 간결한 테스트 코드 지향 (테스트 코드도 지속적으로 리팩터링 해줘야 함)
- 각각의 테스트는 독립적이어야 하며 서로 의존해서 안됨
부록. Test Code 오해와 진실
1. 일정 때문에 테스트 코드 구현할 시간이 없어요!
테스트 코드를 구현하는 것은 Production 코드만 구현하는 것 대비 실제 구현 코드량이 증가하기 때문에 상대적으로 구현 시간이 더 소요되는 것은 맞습니다. 하지만 제 경험상 구현된 코드를 테스트 코드 없이 검증 및 디버깅하는데 소요되는 총시간을 고려하면 비슷하거나 적다고 자신 있게 말씀드릴 수 있습니다. 테스트 코드가 없다면 회귀 오류를 반복적으로 수동 검증해야 하고 이 시간까지 포함한다면 테스트 코드가 없을 때 더 많은 시간이 소요됩니다. 또한 테스트 코드가 존재하지 않은 경우 리팩터링 risk가 너무 커서 리팩터링을 주저하게 되고 이는 자연스레 운영 비용 증가를 야기시키므로 테스트 코드 구현할 시간이 없다는 것은 이유가 되지 않는다고 생각합니다.
2. TDD == 테스트 코드 구현?
테스트 코드 구현을 TDD라고 오해하시는 분들을 종종 보게 됩니다. TDD(Test Driven Development)는 테스트 주도 개발의 약자로 짧은 개발 주기의 반복에 의존하는 개발 프로세스이며, 애자일 방법론 중 하나인 eXtream Programming(XP)의 ‘Test-First’ 개념에 기반을 둔 방법론이며 이의 부산물이 테스트 코드이기 때문에 TDD는 테스트 코드(구현)와는 맥락이 전혀 다르니 오해하시면 안 됩니다. 참고로 TDD는 실패하는 테스트를 먼저 작성하고 이를 성공시키는 Production code를 작성하고 리팩터링 하는 Cycle을 반복적으로 수행하여 애플리케이션을 점진적으로 구현하게 됩니다.

3. Private method를 테스트해야 하나요?
답을 먼저 확인해 보기 위해 링크를 클릭해 보세요!
답은 NO!입니다. 얼마나 많은 개발자들이 이 질문을 했는지, 아예 도메인을 구입해서 대답을 적은 사이트까지 만들어 놓은 회사가 있을까요?😊 좀 더 명확하게 의견을 덧붙이자면, private method의 로직은 반드시 테스트되어야 합니다. 여기서 하지 말라는 말은 private method를 직접적으로 테스트하지 말라는 얘기입니다.
일부 개발자분들이 private method를 테스트하기 위해 접근 지정자를 protected로 바꾸거나 public으로 변경한 후 테스트 종료 후, private로 바꾸는 경우를 볼 수 있는데요. 테스트 코드 실행 때문에 Production code의 디자인이 변경되는 건 올바르지 않습니다.
자, 그럼 private method를 직접적으로 테스트하지 않고서 어떻게 테스트가 가능한지 알아보도록 하겠습니다. 일반적으로 테스트 코드 구현은 다음과 같은 Cycle을 가지게 됩니다
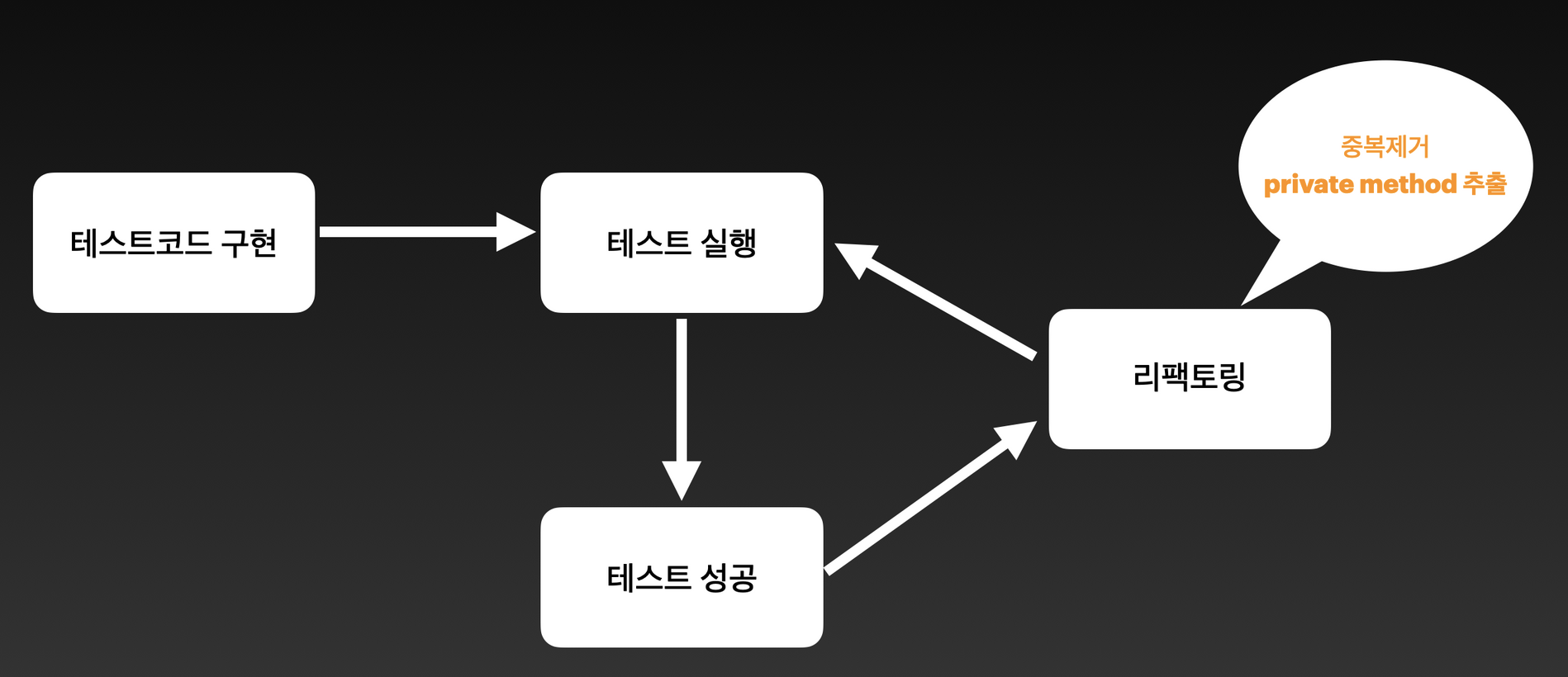
먼저 테스트 코드를 구현한 다음 테스트를 실행하고 테스트를 성공시킨 이후 테스트 코드를 믿고 Production 코드를 리팩터링 하게 됩니다. 리팩터링의 전제 조건은 리팩터링 이전과 이후 동일한 실행 결과를 보장해줘야 하는 것입니다. 동일한 실행 결과에 대한 보장 검증은 앞서 구현한 테스트가 코드가 해주게 되는 것이죠~ 리팩터링 시에는 주로 중복 제거 및 특정 로직을 의미 있는 메서드로 추출하게 되는데 이렇게 추출된 메서드는 외부 접근이 불가능하도록 가시성을 private으로 정의하게 됩니다. 리팩터링이 끝났다면 실행결과가 동일한지 테스트를 통해 검증하고 성공하면 끝나게 됩니다. 우리는 private method를 추출하는 리팩터링 단계를 거쳤지만 private method를 직접 테스트하지 않았고 기존 테스트 케이스는 정상적으로 성공시켰습니다!
여기서 앞서 설명드린 무엇을 테스트해야 하는가를 다시금 떠올려 보면
"Application Design(명세)를 테스트하라!"
테스트 코드(case)가 SUT의 명세 기반하에 작성되어 있다면 명세가 변경되지 않는 한 내부 구현이 어떻게 변경되든(private method 추출 등...) 테스트 케이스는 Production의 변경사항을 검증할 수 있게 됩니다. 그러므로 private method는 직접적으로 테스트하지 않아도 되는 것입니다.
4. Test Coverage 율이 높으면 좋은 테스트인가?
Test Coverage 율을 올리는 게 목적이 되어버리면 불필요한 테스트 코드가 만들어질 가능성이 농후하게 됩니다. 예를 들면 적절한 검증 단계가 없는 그냥 SUT의 메서드 호출만 하는 형태의 Test case 구현이 있을 수 있습니다. 분명 T.C에서 호출하였으므로 production code의 some logic은 실행이 되었을 것이고, 일정량의 Test Coverage율은 높아졌을 것입니다. 하지만 의미 있는 테스트 코드가 만들어진 건 아닙니다. 명세 기반하에 촘촘히 잘 짜인 T.C는 자연스레 Test Coverage 상승으로 이어지게 되며 너무 맹목적으로 Test Coverage를 높일 필요는 없으며 Test Coverage가 높다고 절대 잘 구현된 테스트 코드라고 말할 수 없습니다.
지금까지 테스트 코드 What? Why? How에 대하여 살펴보았습니다.
테스트 코드 구현의 경우 책 몇 권 또는 강의 몇 시간을 들었다고 그 지식이 바로 구현으로 이어지기 어려운 영역입니다. 테스트 코드를 구현하다 보면 반복적이고 귀찮은 작업들이 수반되게 되는데 이때 많은 수의 개발자분들이 테스트 구현을 포기하게 됩니다. 하지만 인내심을 가지고 계속해서 수련하다 보면 분명 테스트 코드가 없으면 불안해서 애플리케이션을 release 하지 못하는 순간이 오게 될 것이고 이렇게 쌓인 의미 있는 테스트 코드들은 여러분의 애플리케이션이 보다 더 견고하고 신뢰성 있는 애플리케이션이 될 수 있게 보장해줄 거라 감히 단언드립니다.
Enjoy test!
감사합니다.

'Tech' 카테고리의 다른 글
| HTTP/2 훑어보고 AWS에 적용해보기 (0) | 2022.05.31 |
|---|---|
| GitHub Actions에서 도커 캐시를 적용해 이미지 빌드하기 (0) | 2022.05.31 |
| 카카오웹툰은 GitHub Actions를 어떻게 사용하고 있을까? (0) | 2022.03.23 |
| http프록시로 mitmproxy를 사용해보자. (0) | 2022.03.07 |
| 프론트엔드와 THE TWELVE-FACTOR APP (0) | 2022.03.07 |