

안녕하세요, 카카오엔터테인먼트에서 FE개발하고 있는 스티브입니다 🙂
저는 12Factor 를 저희 서비스의 FE 영역에서 어떻게 이해하고 적용했는지 써볼까 합니다. 저희가 사용하고 있는 프레임워크인 Next.js 위주로 작성되었지만 원칙에 대한 내용이기 때문에 다른 기술을 사용 중이어도 도움이 될 거라 생각합니다.
The Twelve-Factor app
혹시 12Factor를 들어보셨나요? (이따금 FE개발자들에게 물어보지만 한 명도 몰랐던…)
12Factor(The Twelve Factors. 이하 12Factor)는 직역하면 12가지 요소를 뜻하지요. 그럼 어떤 것을 위한 12가지 요소일까요? 공식 웹사이트에 잘 설명되어있지만 제가 이해한 대로 한 줄 요약하면 독립적인 애플리케이션 운영을 위한 12가지 요소로 요약할 수 있습니다. 여기서 독립적인은 사람, 시간, 환경 등 애플리케이션 운영 시 영향을 받는 많은 것으로부터의 독립을 뜻합니다.
12Factor는 BE(Back-end) 영역, 특히 DevOps나 Cloud 관련 영역에서 필수 원칙으로 알려져 있습니다. 십계명과 같은 위상이라 하여도 과언이 아니죠. 그 이유는 애플리케이션을 독립적으로 만들 때 충분히 검증됐고 확실한 방법이기 때문입니다. 예를 들면 12Factor 원칙대로 애플리케이션을 구성하면 자연스럽게 환경(IDC, OS, 등)으로부터 독립됩니다. Cloud Native 한 애플리케이션이 되니 쿠버네티스나 AWS 어디든 올릴 수 있게 됩니다. 또한 사람(개발자, 타 팀 사람)으로부터 독립되니 자연스럽게 개발과 운영이 분리되어 DevOps 도입이 수월해집니다. 그러니 BE 영역에선 일단 지키고 보는 필수 원칙이 되었습니다. 사실 BE 영역의 프레임워크(대표적으로 Spring Boot) 방향성이 12Factor를 기반으로 발전해가니 자연스레 지켜지는 측면도 있죠.
그럼 FE개발자도 알아야 할까요? 저는 애플리케이션을 개발하고 운영한다면, FE개발자도 알면 좋은 부분이라 생각합니다. 참고로 카카오엔터테인먼트에서 노드 서버(Next.js)로 서비스 중인 카카오페이지, 카카오웹툰은 FE개발자가 직접 운영하고 있습니다. 특히나 점차 FE개발의 스펙트럼이 서버 영역으로 넓혀지고 있는 지금이라면 더욱 필수라 생각하구요. 최근 Next.js 에서 API Routing, Middleware를 내보이고 있고 React 에서도 Node 서버에서 렌더링되는 컴포넌트를 출시한 것을 보면서 더욱 확신이 들었습니다. 물론 SSR 등의 서버 영역을 도입하지 않은 개발팀에게는 몇 가지 원칙(6,7,8,9,12번)은 큰 의미가 없겠지만 나머지 원칙은 개발 및 운영에 중요한 지침이 될 거라 생각합니다.
이 글에서는 FE개발자인 우리가 어떻게 12Factor를 이해해야 하는지 알아보고 실제 서비스에서 어떻게 도입했는지 하나하나 얘기해보겠습니다.
I. 코드베이스
목표 : 버전 관리되는 하나의 코드베이스와 다양한 배포
사소해 보이지만 가장 중요한 원칙입니다. 12Factor 애플리케이션의 기본(베이스)이라 할 수 있는 부분입니다. 하나의 코드베이스는 하나의 앱을 가지고 있어야 합니다. 이를 위반한 케이스 중 하나는 바로 그 유명한 모놀리식(Monolithic) 입니다.
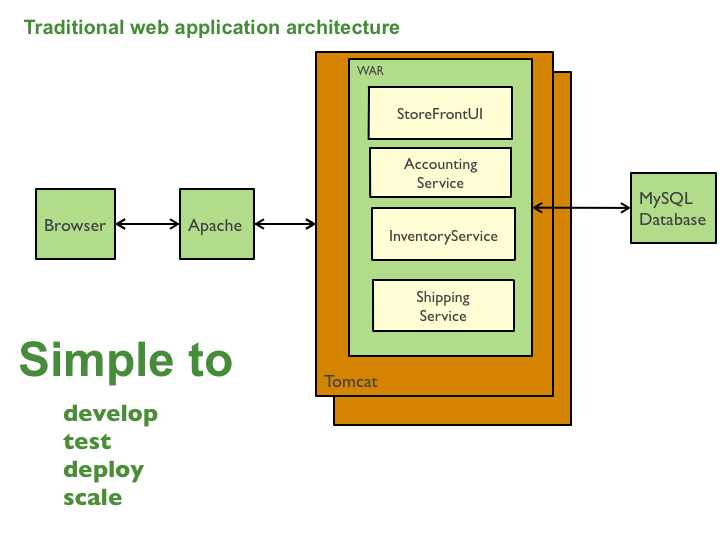
전통적인 모놀리식 구조 - 출처 : 크리스 리차드슨 마이크로서비스
일반적으로 서비스의 규모가 작을 땐 한 팀에서 모놀리식으로 개발됩니다. UI 관련 코드도 같은 코드베이스에 존재하죠. 그러다 서비스 규모가 커지면서 점차 사람이 늘어나고 팀도 하나 둘 늘어나게 됩니다. 회원팀, 상품팀, 주문팀, 그리고 FE팀 등등 팀이 늘어나는데 하나의 모놀리식을 유지하는 경우가 있습니다. 이 경우 하나의 코드베이스로 여러 다양한 서비스를 배포하니 코드베이스 원칙 위반입니다. 제가 경험했던 프로젝트 중에 많게는 120명이 하나의 모놀리식으로 개발하는 경우도 있었습니다. 이 정도 수준이 되면 각 작업자들 간의 의존도가 너무 높아 상시 배포가 불가능해집니다. (매주 목요일 새벽에 대부분의 개발자가 출근해 정기 배포를 진행해야 했죠). 많은 회사에서 MSA(Micro Service Architecture)를 통해 코드베이스를 분리하는데요, 그 근거가 되는 것이 바로 12Factor의 첫 번째 원칙인 코드베이스 입니다.
하지만 코드베이스 원칙 하나만으론 레포(Repository)에 대한 명확한 기준을 잡기 어려운 경우가 있습니다. 예를 들면 최근 각광받고 있는 모노레포는 어떨까요? 모노레포는 하나의 레포에서 여러 개의 앱을 배포할 수 있는데요, 이 경우 코드베이스 위반일까요?
답부터 얘기하자면 위반이 아닙니다.
코드베이스와 레포는 목적이 다릅니다. 12Factor에서 얘기하는 코드베이스 는 배포와 관련되어있고, 레포 는 업무 수행과 관련되어있다고 볼 수 있습니다.
레포 를 어떻게 할 것인지도 코드베이스 와 마찬가지로 애플리케이션을 구성하는 시작점에서 가장 중요한 결정 중 하나로 볼 수 있습니다. 여기에 대해선 콘웨이 법칙(Conway's law)이라는 명확한 이정표가 있습니다. 일반적으로 12Factor의 첫 번째 원칙을 얘기할 때 콘웨이 법칙도 같이 거론됩니다. 콘웨이 법칙은 다음과 같습니다.
소프트웨어 구조는 해당 소프트웨어를 개발한 조직의 커뮤니케이션 구조를 닮게 된다. - 콘웨이
다양한 곳에 적용할 수 있는 법칙입니다. 지금까지 많은 개발팀을 거쳐왔는데 이 법칙을 벗어난 적이 없습니다. 조직의 커뮤니케이션 구조는 정말로 코드나 서비스 아키텍처에 그대로 녹아져 있습니다. 업무 수행과 관련된 레포 는 콘웨이 법칙으로 명확하게 제안할 수 있습니다. 하나의 레포는 단일팀에서만 이용해야 합니다. 만약 여러 팀에서 하나의 레포를 이용하게 되면 필연적으로 공통 코드가 생기게 되고, 개발과 운영 시 다른 팀 작업분과 의존성이 발생하게 됩니다. 결국 여러 팀이 하나의 레포를 사용하듯이, 하나의 커뮤니케이션 구조로 들어오게 됩니다. 반대도 콘웨이 법칙이 적용됩니다. 하나의 팀에서 여러 레포를 사용하게 되면 각 레포의 담당자 간 사일로(Silo)가 발생합니다.
모노레포는 각각의 패키지가 별도의 코드베이스가 되기 때문에 12Factor를 위반하지 않습니다. 또한 해당 레포 를 관리하는 팀은 단일팀이기 때문에 콘웨이 법칙으로 볼 때도 괜찮은 커뮤니케이션 구조를 갖습니다.
첫 번째 원칙인 코드베이스에서 가장 중요한 것은 서비스 간 의존성을 낮추고 독립된 커뮤니케이션 구조를 유지하는 것입니다. 이를 만족하면 자연스럽게 독립된 배포 환경에 도달하게 됩니다. 이는 곧 팀의 작업 속도 향상을 가져오고 서비스의 성장과 속도에도 영향을 끼치게 됩니다.
II. 종속성
목표 : 명시적으로 선언되고 분리된 종속성
두 번째 원칙인 종속성에서 강조하는 것은 외부 시스템으로부터의 독립입니다.종속성은 FE에서 어느 정도 잘 실천하고 있는 원칙이라 생각합니다. 애플리케이션 실행에 관련된 의존성을 package.json 에 선언하면 의존성 관리툴(npm, yarn)을 통해 손쉽게 설치하고 실행할 수 있습니다.
하지만 12Factor에선 조금 더 넓은 범위의 종속성을 얘기하고 있습니다.
Twelve-Factor App은 전체 시스템에 특정 패키지가 암묵적으로 존재하는 것에 절대 의존하지 않습니다. 종속선 선언 mainifest를 이용하여 모든 종속성을 완전하고 엄격하게 선언합니다. 더 나아가, 종속성 분리 툴을 사용하여 실행되는 동안 둘러싼 시스템으로 암묵적인 종속성 “유출”이 발생하지 않는 것을 보장합니다. 이런 완전하고 명시적인 종속성의 명시는 개발과 서비스 모두에게 동일하게 적용됩니다.
The Twelve-Factor Dependencies 부분
암묵적인 종속성은 여러 가지가 있지만, FE개발에선 대표적으로 Node.js 버전이 있습니다. 코드에서 사용 중인 Node.js 버전을 package.json(volta), 혹은 .nvmrc(nvm) 에 명시해 종속성을 관리해야 합니다.
또한 package.json 에 정확한 버전(^, ~ 제거) 사용과 lock 파일을 통해 종속성을 고정(Dependency Pinning) 해야 합니다.
마지막으로 필수는 아니지만 강하게 제안하는 것은 OS, 실행환경에 대한 암묵적인 종속성을 벗어나기 위해 도커 컨테이너화 하는 것입니다.
III. 설정
목표 : 환경(environment)에 저장된 설정
애플리케이션을 운영하려면 반드시 환경(개발, 스테이징, 프로덕션 등)이 분리되어있어야 합니다. 환경별로 달라질 수 있는 예시는 다음과 같습니다.
- API 정보
- CDN 정보
- 로깅 레벨
- etc….
12Factor의 세 번째 원칙인 설정 은 이러한 환경별 변수를 코드 내부에 두지 않고 외부로부터 주입 받음으로써 환경으로부터 독립을 완성하는 원칙입니다.
Next.js 에서 공식적으로 제공하는 Environment Variables 를 통해 환경을 분리할 수 있는데요, 이 방법은 엄밀히 보면 설정 원칙을 위반한 방법입니다.
예를 들면, Next.js 프로젝트에선 아래 절차대로 API_HOST 를 환경별로 분기할 수 있습니다.
.env.local파일 생성- API_HOST 정보 기입
API_HOST=https://local.api.com/ - 클라이언트단 코드에서
NEXT_PUBLIC_API_HOST사용useEffect(() => { fetch(`${NEXT_PUBLIC_API_HOST}/api/my_series`) }, []); next build
위와 같이 개발할 경우 웹팩이 돌면서 모든 NEXT_PUBLIC_API_HOST 를 https://local.api.com/ 로 치환(replacement)하게 됩니다.
useEffect(() => {
// NEXT_PUBLIC_API_HOST 가 치환되어 번들됨
fetch(`https://local.api.com/api/my_series`);
}, []);어떤 부분이 12Factor의 설정 원칙을 위반했을까요? 바로 빌드 종속성 이 생긴 부분입니다. Next.js 에서 기본으로 제공하는 환경변수 방식은 빌드 시 문자열을 치환해버리기 때문에 반드시 빌드를 진행해야만 합니다. 이 말은 즉, 서버를 띄우는 런타임에 환경변수를 변경할 수 없게 됩니다. 만약 동일한 코드를 다른 환경(개발 -> 스테이징)에 배포한다면 반드시 다시 빌드해야 합니다.
이러한 구조는 다양한 문제를 야기할 수 있습니다. 일반적으로 프로덕션에 배포되기까지 여러 환경을 거치게 되는데요, 각 환경별로 빌드하게 된다면 빌드 타이밍에 따라 결과가 달라질 수 있는 여지가 생깁니다. 이는 결국 빌드 결과물에 대한 신뢰도에 영향을 끼치고 잠재적인 문제들에 노출될 수 있습니다.
Next.js 에선 이런 상황을 우회하기 위해 설정을 런타임에 주입할 수 있는 runtimeConfig 를 제공합니다.
// next.config.js
module.exports = {
publicRuntimeConfig: {
API_HOST: process.env.API_HOST,
},
}이 방법을 사용하면 브라우저에서도 런타임에 주입된 API_HOST 를 읽어올 수 있습니다.
import getConfig from 'next/config'
const { publicRuntimeConfig : { API_HOST } } = getConfig();주의할 점 하나는 Next.js 의 Automatic Static Optimization 이 적용된 페이지의 경우 getConfig() 가 undefined 가 됩니다. 이유는 특정 조건을 만족했을 경우 SSR(Server Side Rendering) 없이 Static HTML 파일을 그대로 서빙하기 때문인데요, 카카오페이지 웹은 Static HTML 을 사용하지 않기 때문에 runtimeConfig 를 적극 활용했습니다. 반드시 Static HTML 을 이용해야 한다면 다른 방식을 추천합니다. 개인적으로 가장 추천하는 방식은 Sidecar로 Nginx 를 띄워 프록시 하는 방식입니다. 혹은 환경변수 URL을 이용하는 방식도 괜찮아 보입니다. 각자 상황에 맞는 적절한 방식으로 구현하는 것을 추천합니다. 저희 서비스 상황에는 환경변수 주입을 구현할 때 runtimeConfig 가 가장 적절하다 판단되었습니다.
하지만 runtimeConfig 를 그대로 사용하려면 아쉬운 점이 꽤 있습니다.
- 비동기로 runtimeConfig 설정하는 것이 불가능합니다.
- 다른 시스템에 환경 변수가 존재하는 경우(Centralized Configuration)
- KMS(Key Management System) 로부터 읽어오는 경우
- Next.js 설정파일(next.config.js) 은 파일명이 고정이라 타입스크립트 사용이 불가능합니다.
카카오페이지 웹에서는 이러한 불편을 해결하기 위해 custom nextConfig 를 이용했습니다.
그리고 12Factor 구현체인 Dotenv 패키지를 이용했습니다.
const envName = process.env.ENV_NAME; // 개발, 스테이징, 프로덕션
const parsedEnv = Dotenv.config({ path: `/env/${envName}` }).parsed || {};
const serverRuntimeConfig = ....;
const publicRuntimeConfig = ....;
const nextConfigJsPath = await findUp('next.config.js');
const nextConfigJs = require(nextConfigJsPath)();
const nextApp = next({
dev: process.env.NODE_ENV !== 'production',
conf: {
...nextConfigJs,
serverRuntimeConfig,
publicRuntimeConfig,
},
});이제 런타임에 환경변수를 변경하는 것이 가능해졌습니다. 한 번의 빌드로 각 환경에서 뿐 아니라 어디든 이식 가능한 애플리케이션이 되었습니다. 세 번째 원칙인 설정을 만족하는 앱이 되었습니다.
$ ENV_NAME=dev npm start # 개발
$ ENV_NAME=staging npm start # 스테이징
$ ENV_NAME=production npm start # 프로덕션
$ ENV_NAME=production LOG_LEVEL=DEBUG npm start # 프로덕션 환경에 로그 레벨만 변경IV. 백엔드 서비스
목표 : 백엔드 서비스를 연결된 리소스로 취급
네 번째 원칙인 백엔드 서비스는 말 그대로 백엔드 서비스로부터 독립을 요구하는 원칙입니다.
여기서 백엔드란 서드파티 서비스로 볼 수 있습니다. FE 의 대표적인 서드파티는 에러 수집 플랫폼인 Sentry가 있습니다. 백엔드 서비스 원칙을 지키기 위해선 각 환경별로 자유롭게 선택할 수 있어야 합니다. 예를들면 로컬 개발시엔 개발 서버에 설치된 Sentry, 프로덕션 배포시엔 클라우드용 Sentry 를 이용할 수 있도록 선택할 수 있어야합니다.
일반적인 FE 환경이라면 대부분 잘 지키고 있는 원칙이라 생각되어 바로 다음 원칙으로 넘어가겠습니다.
V. 빌드, 릴리즈, 실행
목표: 철저하게 분리된 빌드와 실행 단계
다섯 번째 원칙인 빌드, 릴리즈, 실행은 개인적으로 아주 중요하게 생각하는 원칙입니다. 이 원칙을 만족해야 개발과 운영의 독립(DevOps) 를 실현할 수 있습니다. 지금까지 본 많은 FE 프로젝트는 대부분 이 원칙과 동떨어져 운영되고 있었습니다. 필자가 지금 팀에서 가장 시급하다 생각해 처음으로 적용한 것도 이 다섯 번째 원칙이었습니다.
빌드, 릴리즈, 실행 원칙이 요구하는 것은 아주 심플합니다. 말 그대로 빌드, 릴리즈, 실행 단계를 철저하게 분리하는 것입니다.
보편적인 Next.js 프로젝트는 다음 프로세스를 통해 코드가 프로덕션에 반영됩니다. git 전략은 git flow 를 쓴다고 가정하겠습니다.
- 개발 중인 코드를 develop 브랜치에 푸시
- CI/CD 통해 개발 서버에 반영(npm install -> next build -> deploy)
- QA 시점이 되어 release 브랜치 생성
- CI/CD 통해 QA 서버에 반영(npm install -> next build -> deploy)
- QA 요청 -> QA 완료
- release -> main 푸시
- CI/CD 통해 프로덕션 서버에 반영(npm install -> next build -> deploy)
사실 크게 나쁘지는 않은 방식입니다. 대부분 큰 문제없이 운영됩니다. 하지만 12Factor에 의거하면 몇 가지 잠재적인 문제가 있습니다.
- 개발에 배포된 코드와 리얼에 반영된 코드가 같다는 보장이 없습니다.
- npm install 마다 반드시 동일한 의존성이 설치된다는 보장이 없습니다.
- next build 마다 반드시 동일한 결과물이 나온다는 보장이 없습니다.
- 각 단계(develop -> QA -> 프로덕션)를 반드시 개발자가 관여해야 합니다. (코드와 배포 간 의존성으로 인해)
- 사실상 버저닝이 불가능합니다. 릴리즈가 분리되어있지 않으니 v1.2.3(SemVer) 같은 버전이 불가능합니다. 버전이 git commit 에 의존합니다. 어찌 분리해도 한 버전을 여러 환경에서 실행해볼 수 없습니다.
- 한번 배포되면 해당 결과물을 다른 환경에서 실행해볼 수 없습니다. (리얼에 배포된 파일을 로컬에서 실행해볼 수 없습니다)
그러면 빌드, 릴리즈, 실행 을 어떻게 분리할 수 있을까요?
일단 III. 설정 원칙을 만족해야 합니다. 릴리즈 된 결과물을 여러 환경에서 실행해볼 수 있어야 분리가 가능해집니다. 설정을 분리했다면 아래와 같이 분리할 수 있습니다.
빌드
모든 종속성을 설치하고 코드를 빌드하며 관련된 에셋을 결합합니다.
$ npm install && next build릴리즈
빌드 단계에서 만들어진 빌드 파일에 배포에 필요한 설정을 결합합니다. 저희는 도커를 이용해 배포에 필요한 모든 설정(환경변수, pm2 등)을 결합했습니다.
COPY . /kakaopage
...
CMD ["pm2", "start", "app.js"] # 환경변수는 도커 run 시 주입배포가 될 파일(Artifact) 를 생성합니다.
$ docker build . -t kakaopage:v1.2.3실행
실행 단계에서는 실행환경에 맞는 환경변수를 주어 실행합니다
$ docker run -d -p 3000:3000 -e ENV_NAME=production kakaopage:v1.2.3이렇게 각 단계가 분리되었을 때 어떤 일이 일어날까요?
- 개발팀에서는 개발을 진행합니다. 코드 변경시마다 빌드를 통해 통합하고 검증합니다(Continuous Integration)
- QA와 릴리즈할 버전을 논의 후 빌드된 코드를 v1.2.3으로 릴리즈 합니다.
- QA에서는 해당 릴리즈를 QA 환경, 스테이징 환경에 올려 테스트해봅니다.
- 릴리즈가 충분히 테스트되면 운영에서 적절한 시점에 배포 후 실행합니다.
차이점이 느껴지나요? 개발 프로세스 자체는 크게 변하지 않았습니다. 가장 큰 차이는 개발과 인프라 간, 그리고 개발과 운영간 의존성이 낮아져 느슨한 결합도를 유지할 수 있다는 점입니다.
또한 팀에서는 12Factor의 다섯번째 원칙까지 도달했을 때 운영중인 Next.js 프로젝트의 독립성이 놀랍도록 높아진 것을 느낄 수 있었습니다.
- 배포 속도가 빨라졌습니다. 기존엔 배포마다 install, build 를 하다보니 15분 내외로 걸렸는데 지금은 1분 내외로 배포가 진행됩니다.
- 배포된 코드의 릴리즈 버전을 손쉽게 확인할 수 있게 되었습니다. (QA 킬링 포인트)
- QA 프로세스가 간단해졌습니다. 기존엔 배포 타이밍도 조율하고 QA팀과의 커뮤니케이션 미스도 잦았는데 지금은 명확한 버전만 전달하면 되니 간단해졌습니다.
- 자연스럽게 Cloud Native 한 앱이 되었습니다. 하나의 릴리즈를 물리 서버와 쿠버네티스 모두에 올려서 테스트할 수 있게 되었습니다.
- 쿠버네티스에 올릴 수 있게 되면서 모든 git 브랜치마다 미리보기 링크를 제공하는 프리뷰 서버를 띄울 수 있게 되었습니다.
많은 사람이 행복해졌습니다!
개인적으로 이 다섯번째 원칙까지 적용하는 것이 12Factor를 적용할 때 가장 중요한 고비라 생각합니다. 지금까지 관찰한 여러 프로젝트 중 다섯가지 원칙을 모두 지킨 프로젝트가 손에 꼽습니다. 그만큼 실천하기 어려운 부분이 많습니다. 왜냐하면 배포 프로세스를 변경해야 하기 때문입니다. 협업자들 간에 협의와 변경 절차가 필요하기 때문에 실천하기 어려울 수 있습니다. 필자가 경험한 바로는 충분히 합리적인 원칙이므로 시간이 걸릴지언정 결국 적용할 수 있었습니다. 이 원칙을 모두 지켰을 때 누릴 수 있는 자유로움과 역동성이 있기 때문에 자신 있게 추천합니다.
VI. 프로세스
목표: 애플리케이션을 하나 혹은 여러개의 무상태(stateless) 프로세스로 실행
대부분의 FE 환경에서는 잘 지키고 있는 원칙입니다. 기본적으로 HTTP 요청은 Stateless 하고, 사용자의 브라우저 환경은 매우 독립적이니까요.
이 원칙에 대해선 발생하기 쉬운 케이스인 스티키(Sticky) 로드밸런싱 방식에 대해 한번 언급하고 넘어갈까 합니다.
로드밸런서는 크게 두 가지 방식으로 나눌 수 있는데요, 한번 요청한 서버를 계속 유지해주는 스티키 방식과 무작위로 분배하는 라운드로빈 방식이 대표적입니다.
이 중 스티키 방식은 12Factor의 여섯번째 원칙인 프로세스 원칙을 위반합니다. 스티키를 구현하기 위해선 사용자 정보를 캐싱하고, 같은 유저의 이후 요청도 같은 프로세스에 전달될 것을 가정하게 되는데 이는 명백한 프로세스 원칙 위반입니다. 로드밸런싱 방식을 선택한다면 반드시 스티키 방식을 빼고 선택해야합니다.
안그러면 다음과 같은 상황을 맞닥뜨릴 수 있습니다. (눈물겨운 경험담입니다)
"개발자님! 제 PC 에선 계속 아이콘이 안나와요!"
"어라? 제 PC 에선 나오는데.. 껐다 켜보시겠어요? 아니면 쿠키도 삭제해주세요. 안되면 음.. 브라우저도 다시 설치해보시고 음.."
알고보니 특정 서버에 문제가 있어 아이콘 파일 업로드가 실패했는데, 로드밸런서 설정이 스티키로 되어있어 특정 PC(IP) 에서만 문제가 발생한 케이스였습니다. 로드밸런서는 스태틱 HTML 파일 배포나 직접 서버를 운영할 때 필연적으로 존재하는 부분이기 때문에 기본적으로 어떤 정책을 갖고 있는지 익혀두는 것이 좋습니다.
VII. 포트 바인딩
목표: 포트 바인딩을 사용해서 서비스를 공개함
쉬어가는 타임입니다.
FE개발 환경에서는 필연적으로 지켜지는 원칙입니다. 보편적인 FE 애플리케이션은 브라우저를 통해 포트 바인딩 된 서비스에 접근합니다. 우리는 잘하고 있습니다 :)
VIII. 동시성(Concurrency)
목표: 프로세스 모델을 통한 확장
여섯 번째 원칙인 프로세스 원칙을 지켰다면 동시성 원칙도 간단하게 지킬 수 있습니다. 프로세스 원칙은 프로세스 내부에 상태(state)가 존재하지 않는 것입니다. 반드시 공유해야 할 상태가 없으니(stateless) 수평으로 확장(scale-out) 할 수 있습니다.
이 특징은 특히 node.js 환경에서 더욱 중요합니다.
node.js 는 싱글 스레드 기반으로 돌아갑니다. node 명령으로 서버를 실행했을 때 단 하나의 스레드만 돌아갑니다. 즉, CPU 중 단 하나의 core만 사용합니다. 보통 작은 시스템도 2개 이상의 코어를 갖고 있는데 기본 node 실행으로 운영하는 건 심각한 리소스 낭비입니다. 프로세스를 수평으로 확장하는 가장 손쉬운 방법은 대표적인 프로세스 매니저인 pm2를 이용하는 것입니다.
카카오페이지 웹은 아래와 같은 설정으로 프로세스 확장을 하고 있습니다.
// ecosystem.config.js
module.exports = {
apps: [
{
// ...
script: './.output/server/index.js', // next.js 번들링된 결과
instances: 'max', // 장비에서 허용하는 최대 코어 수만큼 프로세스 확장
exec_mode: 'cluster', // 모든 CPU를 사용하기 위해선 cluster 모드 사용
// ...
},
],
};// package.json
...
"start": "NODE_ENV=production pm2-runtime start ecosystem.config.js"
... ...
# 프로세스 매니저(pm2) 글로벌 설치
RUN npm install -g pm2
...
CMD ["npm", "start"]위와 같이 설정하면 아래처럼 core가 8개인 장비에 코어만큼 프로세스가 떠 있는 것을 볼 수 있습니다. Next.js 프로젝트는 HTML 생성 시 CPU 자원을 많이 소비하기 때문에 꼭 필요한 조치라고 볼 수 있습니다.
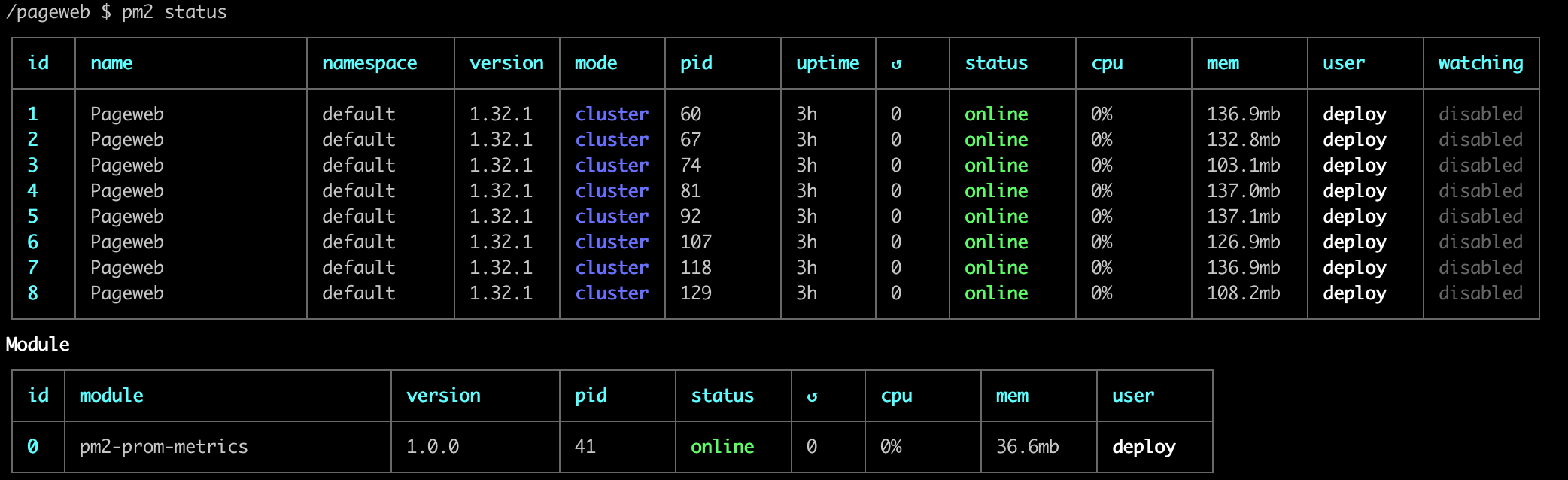
IX. 폐기 가능(Disposability)
목표 : 빠른 시작과 그레이스풀 셧다운(graceful shutdown)을 통한 안정성 극대화
애플리케이션 종료를 안전하게 할 수 있는 것을 Graceful Shutdown 이라 합니다. 대부분의 서버는 이 부분을 잘 수행해주기 때문에 크게 고려하지 않아도 됩니다. 그래도 상식선에서 꼭 알고 있는것이 좋습니다.
서비스가 PID 1234 로 돌아가고 있다고 가정 해보겠습니다.
$ kill 1234 # node.js 가 돌아가고있는 프로세스ID어떤 일이 일어날까요? 기본 kill 명령을 날렸을 때 SIGTERM(15) 시그널이 전달되는걸 알고 있나요? 이 시그널은 "안전하게 종료해" 라는 시그널입니다. 우리의 node.js 서버는 이 명령을 받으면 더 이상의 추가요청 받는 것을 중단하고 이벤트 루프가 비어질 때 까지 대기합니다. 그리고 모든 큐가 비워지면 프로세스를 종료합니다. SIGTERM 명령은 범용적으로 쓰이는 명령어고 AWS 나 쿠버네티스 등에서 컨테이너를 종료할 때 먼저 전달하는 시그널이니 상식선에서 꼭 알고 있어야합니다. 프로세스 종료 관련해서는 이 글에 잘 정리되어있습니다.
혹시 이 글을 읽는 독자 중 다음처럼 프로세스를 종료하고 있다면 당장 바꿔야합니다. (놀랍게도 제가 경험한 프로젝트중 정말로 이렇게 종료하는 경우가 있었습니다)
kill -9 1234 # SIGKILL(9) 프로세스 즉시종료(NOT SAFE)X. 개발/프로덕션환경 일치
목표: 개발, 스테이징, 프로덕션 환경을 최대한 비슷하게 유지
개인적으로 아주 좋아하는 원칙입니다. 다른 원칙보다 강제성이 크지 않습니다. 하지만 개발자를 행복하게 만드는 정책 으로 볼 수 있습니다.
골자는 "개발, 스테이징, 프로덕션 각 환경 사이에 차이가 없도록 하자" 입니다. 이 차이는 대표적으로 시간, 담당자, 툴 세 가지가 있습니다.
| 전통적인 애플리케이션 | 12Factor App | |
|---|---|---|
| 배포 간의 간격 | 몇 주 | 몇 시간 |
| 코드 작성자와 코드 배포자 | 다른 사람 | 같은 사람 |
| 개발 환경과 프로덕션 환경 | 불일치함 | 최대한 유사함 |
출처 : 12Factor 공식 웹페이지
시간은 배포되는 코드에 대한 기억력과 관련 있으니 간격이 작을수록 좋고, 배포 시 어떤 이슈가 생길지 모르니 코드 작성자도 같이 모니터링하는 것이 좋습니다. 그럼 개발 환경과 프로덕션 환경이 최대한 유사해야할 이유는 무엇일까요?
이유는 잠재적인 위험 요소를 빠르게 파악하기 위해서입니다. 개발 환경과 프로덕션이 다를 경우, 프로덕션에 배포하기 전에는 이슈를 파악하지 못하는 경우가 왕왕 발생합니다.
예를들면 아래와 같이 개발과 프로덕션간 적용 여부나 정책이 달라서 코드가 프로덕션에 배포된 후에 뒤늦게 문제를 발견하게 될 수도 있습니다.
- https 적용 여부, 인증서 종류 -> Mixed Content, 인증서 신뢰도 등
- CDN 정책 -> web 2.0 버전, 캐싱 등
- 백엔드(API) 서버 정책 -> 이중화, CORS, timeout 등
- 서드파티(Sentry, SDK)
- 데이터 -> 포맷, 글자 길이 제한 등
- 등등..
이 원칙은 아무래도 정책 관련된 내용이니 단일 팀에서만 진행하기는 곤란한 면이 있습니다. 개발/프로덕션환경 일치 원칙은 여러 사람, 팀, 서비스에 얽혀있는 부분이다보니 시간을 갖고 천천히 적용해가야 할 원칙입니다. 어렵겠지만 하나씩 맞춰가다 보면 어느 순간 개발환경이 확연히 좋아지는걸 느낄 수 있는 원칙이기도 합니다. 개발 환경이 프로덕션 환경과 유사하게 될수록 장애 발생율이 감소하고 개발자도 더욱 자신감 있게 개발할 수 있습니다
XI. 로그
목표: 로그를 이벤트 스트림으로 취급
FE개발자들은 클라이언트로부터 CS가 들어왔을 때 부디 테스트 기기에서도 재현되길 기도하며 CS 내용대로 테스트를 진행해봅니다. 재현되면 다행이지만 사용자 환경이 워낙 다양해 재현되지 않는 경우도 많습니다. 이때 사실상 의지할 곳은 로그밖에 없습니다. 이슈를 얼마나 빠르게 파악할 수 있는지는 결국 로그 시스템이 얼마나 갖춰있고, 이슈 트래킹이 얼마나 간편한지에 달려있습니다.
서버개발 시 로그의 중요성은 이루 말할 수 없을 정도로 높은 반면 FE 영역에서는 상대적으로 중요도를 낮게 보는 경향이 있는 것 같습니다.
열한 번째 원칙인 로그 는 일단 그 중요성을 기저에 깔고 갑니다. 로그의 중요성은 아무리 강조해도 지나치지 않습니다. 서버든 클라이언트든 열심히 로그를 남기는 게 기본이라 가정했을 때,
손쉽게 로그를 남기고 수집함으로써 종내엔 중앙화된 로그 분석 시스템을 통해 열람하는 것을 목표로 합니다.
카카오페이지 웹팀에서는 아래 네 가지 로그를 수집해 이슈트래킹 시 참고하고 있습니다.
- 미들웨어 엑세스 로그(Nginx)
- 애플리케이션 에러 로그(Sentry)
- 서버사이드 로그
- 클라이언트사이드 로그
모두 중요한 로그라 하나하나 짚어보겠습니다.
엑세스 로그
엑세스 로그를 통해 사용자 브라우저 종류, IP 주소, 요청 소요 시간, HTTP 상태 코드 등을 볼 수 있습니다. Next.js 를 사용한다면 대부분 서버사이드렌더링을 이용하기 때문에 HTTP 상태 코드가 더욱 중요합니다. 서버사이드렌더링 시 4XX~5XX 에러가 발생하면 사용자에게도 같은 에러 코드와 함께 에러 화면을 보여주게 됩니다. 엑세스 로그 중앙화가 잘 되어있다면 해당 에러 발생 시 알람을 받을 수 있고, 사용자 환경을 유추할 수 있는 브라우저 버전, IP 주소 등을 빠르게 확인할 수 있습니다.
엑세스 로그는 AWS 를 사용한다면 CloudWatch 같은 모니터링 시스템을 통해 수집과 시각화를 간단하게 할 수 있습니다. 별도 인프라를 운영중이어도 로그 수집 자체는 어렵지 않습니다. 엑세스 로그를 시각화할 때 가장 많이 사용하는 방식이 ELK Stack(Elasticsearch + Logstash + Kibana) 인데요, 아마 소속된 조직에서 크거나 작게 사용 중인 스택일 것으로 생각합니다. FE개발자가 할 일은 해당 스택 관리자에게 엑세스 로그 수집을 부탁하거나, 직접 filebeat 를 설치해 logstash 로 전달하는 작업 을 하면 됩니다. 여기까지는 FE개발자도 손쉽게 할 수 있습니다. 나머지 logstash, elasticsearch, kibana는 사내에 (아마도) 존재할 데이터 관련 팀에 부탁하면 됩니다. 관련 팀이 없다면 조금(?) 발품팔면 직접 구축할 수도 있습니다. 정말 중요한 로그니 만약 수집중이 아니라면 꼭 수집하는 것을 추천합니다.
애플리케이션 에러 로그(Sentry)
SSR/CSR 모두 Sentry 로 에러를 수집하고 있습니다. 크게 특별한 점은 없습니다.
서버사이드 로그
서버사이드렌더링 시 발생하는 로그는 Winston 을 통해 로그를 남깁니다. 로그는 로그양을 추산해 500m 단위로 rotate 하고 스토리지를 과하게 차지하지 않도록 파일 제거 옵션을 추가합니다. 로깅 레벨(ERROR, WARN, INFO, DEBUG)을 환경변수로 제어하기 위해 silly 로 놓고 내부 로직을 통해 제어합니다. 저희가 사용 중인 옵션 중 중요한 부분을 공유합니다.
const combinedCustomFormat = combine(
customTimestamp(),
customFormat,
splat(),
);
const transports = [];
const DailyRotateFile = winstonDailyRotateFile;
transports.push(
new DailyRotateFile({
filename: 'logs/application-%DATE%.log',
format: combinedCustomFormat,
datePattern: 'YYYY-MM-DD',
// 파일이 500m 이상이면 rotate 된다. (뒤에 .1, .2 식으로 넘버링된다) 물론 하루가 지날때도 rotate 된다.
maxSize: '500m',
// 로그 파일(gz 미포함)이 15개 넘으면 예전 파일을 삭제한다
maxFiles: 15,
// gzip 파일이 삭제되지 않는 버그가 있어 압축하지 않는다. (버그 : https://github.com/winstonjs/winston-daily-rotate-file/issues/125)
zippedArchive: false,
}),
);
return winstonCreateLogger({
// 모든 로그를 보여주되, 로그 레벨 컨트롤은 커스텀 환경변수를 이용한다
level: 'silly',
format: combinedCustomFormat,
transports,
});여기까지 설정했을 때 Node.js 의 이벤트루프 특성으로 인한 아쉬운 부분이 있었습니다. 바로 사용자의 요청에 의해 여러 함수가 실행되었을 때, 해당 함수들 간의 컨텍스트를 표현할 방법이 없다는 것이었습니다.
예를들면 사용자가 나 혼자만 레벨업 웹툰 최신화를 클릭했을 때 아래 함수가 호출된다고 가정해보겠습니다.
async function view(viewerId, userId){
logger.info("[VIEWER]-[OPEN] viewerId: %s, userId: %s", viewerId, userId)
try {
await checkUserCanRead();
await useTicket();
} catch (err) {
logger.err("[VIEWER]-[ERROR] reason: %s", err.message, err);
...
}
}위의 view 함수에서는 두 번의 로그를 남기고 있습니다. 뷰어를 오픈했을 때 info 로그를, 에러 상황에서 err 에러를 남기고 있습니다. 그럼 실제로 에러가 발생했을 때 어떻게 로그가 남을까요?
2021-09-13 23:23:39.385+09:00 info : [VIEWER]-[OPEN] viewerId: 1234, userId: 555
2021-09-13 23:23:39.385+09:00 info : [VIEWER]-[OPEN] viewerId: 5678, userId: 342
2021-09-13 23:24:39.385+09:00 err : [VIEWER]-[ERROR] reason: 탈퇴한 유저입니다어찌보면 너무 당연한 사실에 많이 당황했습니다. 위 로그처럼 에러가 발생했을 때 어떤 요청으로부터 이어진 것인지 파악할 수 없다는 점이 충격으로 다가왔습니다. 그렇다고 로그를 남길 때마다 모든 필요한 정보(여기선 viewerId, userId)를 넘기는 건 너무 아름답지 않게 보였습니다.
로그를 남겼을 때 하나의 요청으로 간주할 수 있는 정보가 필요했습니다. 자바 진영의 Thread Id 처럼요. 예를들면 아래처럼 한번의 요청(request) 에 호출되는 여러 함수를 관통할 수 있는 id 가 필요했습니다.
2021-09-13 23:23:39.385+09:00 info --- [51234111]: [VIEWER]-[OPEN] viewerId: 1234, userId: 555
2021-09-13 23:23:39.385+09:00 info --- [41434234]: [VIEWER]-[OPEN] viewerId: 5678, userId: 342
2021-09-13 23:24:39.385+09:00 err --- [51234111]: [VIEWER]-[ERROR] reason: 탈퇴한 유저입니다하지만 사실상 Node.js 는 싱글 스레드 구조라 기본 기능으로는 불가능한 방식이었습니다. 모두 동일한 스레드에서 돌아가기 때문에 다른 언어의 ThreadLocal 개념이 없었습니다. 그렇게 불가능할 것으로 생각하고 포기할까 하는 순간 Node.js 의 실험적인 기능인 async_hooks 가 검색엔진에 걸렸습니다. 내부에서 검토해본 결과 사용해도 괜찮다는 확신이 들어 2년 전 실서비스에 적용했고, 지금까지 문제 없이 완벽하게 동작하고 있습니다. async_hooks 에 대한 개념은 NodeJS에서 async_hooks을 이용해 요청의 고유한 context 사용하기 글에 아주 잘 정리되어있습니다.
저희는 async_hooks 를 손쉽게 사용하도록 래핑한 express-http-context 를 이용했습니다.
// express-http-context 미들웨어 등록
server.use(httpContext.middleware)
...
server.get("/viewer", (req, res) => { // 최초 요청 시 httpContext 세팅
httpContext.set('contextId', uuidv4()) // 랜덤한 값을 생성해 contextId 등록
})
...
// 코드 전체에서 공용으로 사용하는 log 함수
function log(logLevel, logMessage){
// httpContext 로부터 contextId 를 가져와 로깅 정보에 추가
winstonLogger.log(logLevel, `[${httpContext.get('contextId')}] : ${logMessage}`)
}이렇게 contextId 를 로그에 남겨주면 로그 분석 시스템에서 이슈 트래킹 시 요청의 흐름을 추적(tracing) 할 수 있기 때문에 상당히 유용합니다.
클라이언트사이드 로그
만약 Next.js 의 getInitialProps 를 사용했다면 이 코드는 SSR/CSR 두 환경에서 모두 동작하기 때문에 클라이언트 로그도 수집해야할 필요가 있습니다. 또한 사용자의 특정 액션을 로그로 남겨 이슈 트래킹 시 활용할 수도 있습니다. 브라우저 로그를 수집하는 방법은 서비스마다 다를 수 있고 조금 민감할 수 있는 부분이라 따로 언급하지는 않겠습니다.
여기서 얘기하고 싶은 포인트는 SSR 과 CSR 에서 남겨지는 로그 사이에 어떻게 컨텍스트를 유지할 수 있는지인데요, 저희는 cookie 를 이용해 컨텍스트를 유지하고 있습니다.
// _app.tsx
function getInitialProps({ ctx: { res } }) {
...
if(isServerSideRendering) {
const contextId = httpContext.get('contextId');
res.cookie(COOKIE_CONTEXT_KEY, contextId, {
..
httpOnly: true,
expires: EXPIRES_DATE,
..
});
}
}브라우저 로그를 수집하는 서버에서 쿠키에 존재하는 contextId 도 남겨주면 전체 플로우를 추적(tracing) 할 수 있습니다.
XII. Admin 프로세스
목표: admin/maintenance 작업을 일회성 프로세스로 실행
드디어 마지막입니다!
마지막 원칙인 Admin 프로세스 는 FE 영역에서는 크게 신경쓰지 않아도 되는 원칙이라 생각합니다.
굳이 적용해보자면 다음 항목들에 적용해볼 수 있습니다.
- 배포 관련 스크립트를 동일 코드베이스에 놓기
- 여러 유틸리티성 스크립트(codegen, git, check eslint 등)를 같은 코드베이스에 놓기
- 동일한 종속성 분리 기술(npm, yarn)을 사용하기. 예를들면 별도 스크립트 실행이 아닌
npm run codegen로 실행하기
맺음말
후아! 쓰다보니 꽤 긴 글이 되었네요. 그래도 꼭 한번 하고 싶던 얘기를 풀어놓을 수 있어 보람찹니다.
마무리는 소프트웨어 공학의 명언 은탄환은 없다 로 하겠습니다. 당연히 The Twelve-Factor 가 정답이 될 수는 없습니다. 각자 상황에 맞게 속도를 맞춰 지혜롭게 적용해나가야 합니다. 위에서 언급한 방식들도 먼저 팀의 업무방식과 히스토리를 먼저 관찰한 뒤 하나하나 논의하며 적용한 방식들 입니다. 언제든 더 좋은 방식을 찾고 변경할 수 있습니다. 중요한 것은 12Factor의 각 원칙이 진정으로 얘기하고자 하는 것이 무엇인지 이해하고 적용해나가는 태도라 생각합니다.
긴 글 읽어주셔서 감사합니다.
끝.
참고 링크

더 많은 FE 지식을 나누고 싶다면?! 카카오엔터테인먼트 FE 기술블로그 [바로가기]
'Tech' 카테고리의 다른 글
| HTTP/2 훑어보고 AWS에 적용해보기 (0) | 2022.05.31 |
|---|---|
| GitHub Actions에서 도커 캐시를 적용해 이미지 빌드하기 (0) | 2022.05.31 |
| Test Code Why? What? How? (0) | 2022.05.17 |
| 카카오웹툰은 GitHub Actions를 어떻게 사용하고 있을까? (0) | 2022.03.23 |
| http프록시로 mitmproxy를 사용해보자. (0) | 2022.03.07 |