

요즘 MSA(Micro Service Architecture)를 많이 사용하게 되는데, 개발하다 보면 다음과 같은 상황들이 펼쳐질 수 있습니다.
- 여러 플랫폼(Web, Android, iOS …)을 지원하게 되면서 각각 특정 데이터가 필요한 상황
- 원하는 데이터 형태에 도달하기 위해 여러 API 호출의 응답을 조작, 혼합, 일치시키는 상황
- 이런 상황들이 겹쳐 프론트엔드에서 복잡한 계산이나 비즈니스 로직을 작성하는 상황
코드 베이스가 커지고 복잡해짐에 따라 정리하기가 어려워지고, 그때쯤이면 코드 베이스가 통제 불능 상태가 되며 버그가 숨어 있는 복잡성을 발견하게 됩니다. 특히 프론트엔드에서 복잡한 계산을 수행하는 경우 렌더링이 느려질 수 있습니다. UI 스레드에서 렌더링과 비즈니스 로직 수행이 경합을 벌이기 때문입니다.
그렇다면 이를 개선하기 위한 방법은 무엇이 있을까요? 일반적으로 사용되는 API 형식과 BFF 구조를 비교하며 살펴봅시다.
일반적인 API 구조
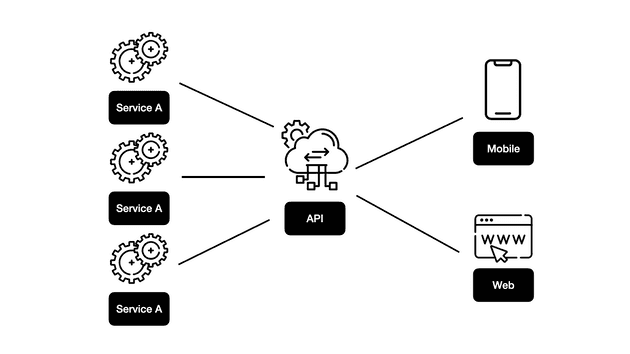
다양한 플랫폼을 지원하는 API는 때로 애플리케이션에서 사용하지 않는 불필요한 데이터가 포함될 수 있습니다.
그림과 같이 여러 플랫폼이 있을 경우, 프론트엔드에서는 동일한 API를 호출하게 됩니다. 백엔드 개발자는 여러 플랫폼의 모든 요구사항들을 충족시키기 위해 모든 데이터를 내려주도록 API를 구현하게 됩니다. 이외에도 백엔드 쪽에서 데이터를 처리하기 위해 필요했던 부가적인 것들을 내려주거나, 단일 페이지에서 여러 API를 호출하는 경우도 발생합니다.
또한, 직접 API에 의존할 때 여러 가지 이슈가 발생할 수 있습니다.
- MSA(Micro Service Architecture) 환경에서 API 엔드포인트가 분리될 때 팔로업 이슈
- 브라우저의 숙명인 CORS 이슈
- API 입장에서 여러 플랫폼과 스펙을 맞출 때의 커뮤니케이션 비용
- 플랫폼별로 다를 수밖에 없는 인증 방식을 통합하려는 무리한 시도
- 클라이언트의 꿈인 ‘화면에 필요한 데이터만 받는’ partial response를 하기 어려운 이슈
BFF 구조
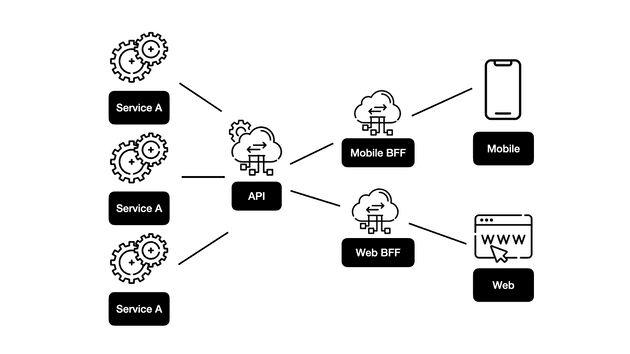
API를 다이렉트로 의존할 때의 이슈들을 해결하고자 BFF가 등장합니다. Backend For Frontend라는 말 그대로 프론트엔드를 위한 중간 서버를 구현하는 것이라고 생각하면 됩니다.
그림과 같이, 하나의 프론트엔드에 대해 하나의 BFF가 있어야 하며 BFF를 프론트엔드 요구사항에 맞게 구현할 수 있습니다. 따라서, 여러 플랫폼을 지원하지 않을 경우에는 BFF가 의미 없을 수 있습니다.
참고로 카카오페이지는 iOS, Android, Web을 지원하고 있고, Web에서만 BFF를 적용을 하고 있습니다.
BFF에서는 프론트엔드 생선성을 더욱 높이기 위해, 데이터를 통합하는 처리를 담당합니다. 또한, BFF를 구현하여 프론트엔드를 백엔드에서 분리된 상태로 유지할 수 있습니다. BFF는 프론트엔드 요구사항을 충족하기 위해 존재하며, 이상적으로는 프론트엔드 개발자가 빌드해야 합니다.
결론적으로, 앞서 얘기했던 API 의존성 이슈들을 BFF 쪽에서 처리를 해줄 수 있습니다.
- MSA 환경에서 API 엔드포인트가 분리될 때 팔로업
- 브라우저의 숙명인 CORS 처리
- API 입장에서 여러 플랫폼과 스펙을 맞출 때의 커뮤니케이션 비용 감소
- 플랫폼별로 다를 수밖에 없는 인증 방식 처리
- 클라이언트의 꿈인 ‘화면에 필요한 데이터만 받는’ partial response
일반적인 API 예시
BFF에서 하는 역할은 다양하지만, 그중에서 ‘여러 API를 호출하는 경우’ 예시를 통해 REST API 호출과 BFF(GraphQL)를 비교하여 응답 값을 어떻게 내려주는지 살펴봅시다.
- GET/user/get_profile
- GET/store/view/cash
// GET/user/get_profile
{
message: "성공"
profile: {
uid: 1234,
nickname: "치즈",
email: "cheese@test.com",
create_dt: "1995-01-31 00:00:00" // 실제 화면에는 필요하지 않은 값
user_id: "5678" // 실제 화면에는 필요하지 않은 값
}
response_time: "2022-03-03 17:49:39" // 실제 화면에는 필요하지 않은 값
result_code: 0
}
// GET/store/view/cash
{
total_balance: 37560
message: "성공"
response_time: "2022-03-03 17:49:39" // 실제 화면에는 필요하지 않은 값
result_code: 0
}일반적으로 각각 API를 호출하게 되면, 응답 값을 그대로 받아서 보통은 가공해서 상태 관리에 저장하게 됩니다. GET으로 호출하게 되면 브라우저의 캐시를 통해 응답 값을 그대로 받아 처리할 수 있겠지만, 매번 상태 관리에서 연산이 필요한 것은 마찬가지입니다.
중요한 것은 위에 있는 데이터와 같이 화면에 필요하지 않은 create_dt, user_id, response_time와 같은 값들이 내려오고 있고 브라우저쪽에서는 두 개의 API 요청을 각각 해야 한다는 점입니다.
GraphQL을 사용하여 BFF를 적용한 예시
graphql은 BFF를 구현하기 위한 구현체로 선택한 부분입니다. graphql를 왜 선택했는지에 대한 자세한 설명은 생략합니다.
궁금하신 분들은 공식 문서를 참고해주세요.
GraphQL로 처리할 때에는 POST로 요청이 발생하고 브라우저의 캐시 대신 라이브러리에서 제공을 해줍니다. 일반적인 AJAX 요청보다 더 쉽게 최적화되기에 Request 개수가 줄어들게 됩니다.
API -> BFF 순서로, 위에 있던 API 응답 값을 BFF에서 받아서 프론트엔드에 필요한 모델 타입으로 변경해서 내려줍니다. GraphQL에서 화면에 필요한 데이터만 가공하게 되면 아래와 같이 바뀌게 됩니다.
- POST/user/get_profile
- POST/store/view/cash
// user.resolver
const resolvers = {
user: async () => {
const response = await kakaopageApi.getProfile();
// createUserWithUserVo 에서 원하는 User 타입에 맞게 가공해줍니다.
return createUserWithUserVo(response.profile);
},
};
// cash.resolver
const resolvers = {
cash: async () => {
const response = await kakaopageApi.getCash();
// createCashWithCashVo 에서 원하는 Cash 타입에 맞게 가공해줍니다.
return createCashWithCashVo(response);
},
};# userAndCash.graphql
query userAndCash() {
userAndCash() {
user() {
...User
}
cash() {
...Cash
}
}
}
fragment User on User {
uid
nickname
email
}
fragment Cash on Cash {
totalBalance
}유저 프로필과 캐시는 한 번에 Resolver에서 둘 다 호출을 하게 되고 두 가지 데이터를 가공해서 내려주도록 합니다. 그리고 실제로 화면에 필요하지 않았던 create_dt , user_id , response_time 같은 것들은 제거된 User와 UserCash 타입을 생성하였습니다. 데이터를 가공하는 과정에서, 필요 없는 것들을 제거하는 것뿐만 아니라 camelCase로 바꾼다든지 날짜 포맷 형식을 바꾸는 등의 처리들을 할 수 있습니다.
이렇게 가공된 데이터를 내려주게 되면, GraphQL에서 캐싱 처리를 하여 프론트엔드 쪽에서는 수정할 필요 없이 데이터를 화면에 그릴 수 있게 됩니다.
Apollo Client의 문제점
이 부분은 저희 팀 Kai 가 정리해주신 내부 공유 글을 인용하여 작성하였습니다.

그림과 같이, Next.js 프로젝트에 Apollo GraphQL을 적용하여 BFF을 구현할 수 있습니다.
BFF를 적용하기 위해 Apollo GraphQL을 사용하려고 보니, Apollo Client는 캐시와 관련해서 문제점이 있었습니다.
Apollo Client의 캐싱 정책은 정규화 캐싱입니다.
query 응답의 각 필드( __typename으로 분리 가능한 모든 객체)를 모두 정규화해서 store에 저장해 두고, 한 번 호출되었던 query는 서버에 요청하는 대신 store에서 캐시 된 데이터로 응답을 내려줘서 서버의 부하를 줄이도록 설계되어 있습니다. 기본적으로 ${__typename}:${id}를 CACHE ID로 사용해 모든 데이터를 store에 저장합니다.
이렇게 id 값을 활용한 방법 때문에 다음과 같은 문제가 발생합니다.
{
layout: {
id: 1
__typename: Layout
sections: [{
id: 1
__typename : Section
groups: [{
id: 1,
category: 1
__typename : Group
},{
id: 2,
category: 2
__typename : Group
},{
id: 3,
category: 1,
__typename : Group
}]
}]
}
}위와 같은 구조의 데이터가 있을 때, categoryFilter variable을 통해 특정 category의 group만 가져오는 getLayout(categoryFilter)를 호출한다고 가정해 봅시다.
1. layout({categoryFilter:1}) 호출
layout({categoryFilter:1}) - Layout:1 - Section:1 - groups[Group:1, Group:3]
처음 호출하는 query이기 때문에 서버에 요청을 보낸 뒤 응답을 받아 위와 같이 CACHE_ID와 참조 관계가 만들어지게 됩니다.
2. layout({categoryFilter:2}) 호출
layout({categoryFilter:2}) - Layout:1 - Section:1 - groups[Group:2]
이 역시 처음 호출하는 query라서 서버에 요청을 보낸 뒤 응답을 받아 위와 같이 CACHE_ID 생성과 함께 참조 관계를 형성합니다.
3. layout({categoryFilter:1}) 재호출
자, 이때는 어떻게 될까요?
cache store에 layout({categoryFilter:1}) 쿼리 결과는 이미 저장되어 있어서 서버에 요청하지 않고 cache store를 확인합니다.
Apollo Client는 참조 응답 값인 Layout:1을 통해 Layout:1 - Section:1 - groups [Group:2]를 반환합니다. 놀랍게도 1번 카테고리 필터를 요청했는데, 2번 카테고리 작품을 받는 불상사가 일어납니다. 이제, 탭을 아무리 바꿔봐도 결괏값은 항상 2번 카테고리 작품이고 화면도 그대로입니다.
이전 layout({categoryFilter:2}) query에 의해 Section:1 데이터가 덮어 씌워지며 일어난 일입니다. 만약 반대 순서로 요청했다면 1번 카테고리 작품만을 반환해 줄 것입니다.
이러한 id 값 캐싱 문제점은 다음과 같은 방법으로 해결할 수 있습니다.
- Section에서 하위 응답 값이 달라지면 그에 따라 식별 가능한 별도의 id를 부여해 주는 것
- Apollo Client에서 제공하는 keyfields를 사용하는 것
물론 해결 방법으로 처리할 순 있겠지만, 카카오페이지는 id 방식으로 캐싱하는 Apollo Client 대신, document 방식으로 캐싱하는 Urql을 사용하게 되었습니다. Urql에 대한 여러 장점도 존재하므로 공식 문서를 참고하시면 좋을 것 같습니다.
카카오페이지에서 BFF를 적용한 구조
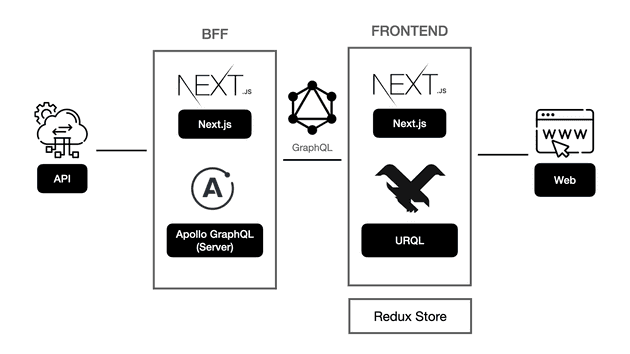
카카오페이지에서 신규 프로젝트를 진행하다 보니 구조를 고민하며 BFF를 적용하게 되었습니다. 프로젝트 구조는 next.js, apollo server, urql, redux로 되어있습니다. 분명 GraphQL을 쓰게 되면, 가공된 데이터를 그대로 캐싱해서 쓰면 된다고 그랬는데 왜 redux가 추가되어 있을까요?
GraphQL + 캐시 이용하는 방식은 한 번의 쿼리를 통해 필터링해서 데이터를 가져오고, 그것을 컴포넌트에서 뿌려주는 방식입니다. 하지만, 그려준 이후에 중간에 있는 데이터를 비동기로 수정하는 건 복잡해집니다.
- 클릭 이벤트가 발생했을 때 data를 비동기로 가져오는 경우
- 스크롤이 도달했을 때 데이터를 가져와서 채워 넣는 경우
이러한 경우에는, 비동기로 데이터를 처리하는 부분이 복잡해지게 됩니다. GraphQL 데이터를 normalize 한 다음에 redux에 넣는 게 최적이라는 팀원들의 의견에 redux까지 도입되었습니다. urql에서 처리하는 부분은 데이터 fetch 하는 쪽이고, 실제 데이터를 저장해서 사용하는 목적인 redux에서의 store를 사용하는 목적은 다르다는 판단이었습니다.
이외에도 에러 처리 같은 것들은 BFF 단에서 커스텀 한 에러 객체로 래핑 하는 구조로 되어있습니다.
마무리
지금까지 BFF의 역할 및 BFF를 적용한 카카오페이지의 구조를 살펴보았습니다.
BFF의 가장 큰 장점은 실제 비즈니스 로직의 구현과 응답 데이터를 클라이언트에서 요구되는 데이터로 파싱 하는 두 가지 관점을 분리하여 복잡도를 낮추고, 필요한 작업에 집중하기 쉬워지는 것이라고 생각합니다.
Next.js + GraphQL 조합을 많이 사용하는 것 같아 조금이나마 구조를 이해하는 데에 도움이 되었으면 좋겠고, 팀마다 상황마다 프로젝트 구조를 가져가는 게 다를 순 있을 거라고 생각합니다. 부족한 글 읽어주셔서 감사합니다 : )
Reference
- BFF - Backend for Frontend Design Pattern with Next.js
- Why I (finally) switched to urql from Apollo Client

더 많은 FE 지식을 나누고 싶다면?! 카카오엔터테인먼트 FE기술블로그 [바로가기]
'Tech' 카테고리의 다른 글
| Technical Writing: 글로 하는 의사소통 (2) | 2022.12.09 |
|---|---|
| 섬세한 ISFP의 코드 가독성 개선 경험 (0) | 2022.12.08 |
| React 합성 컴포넌트로 재사용성 극대화하기 (0) | 2022.09.26 |
| HTTP/2 훑어보고 AWS에 적용해보기 (0) | 2022.05.31 |
| GitHub Actions에서 도커 캐시를 적용해 이미지 빌드하기 (0) | 2022.05.31 |